

文字コードって結局なに?とは!!?
💡 ASCIIやUnicodeなどの文字コードの種類や特徴を、わかりやすく解説します。
💡 日本語で使われているJISコードについても、詳しく紹介します。
💡 このパートでは、文字コードの基礎知識を身につけましょう。
文字コードについて、これから詳しく見ていきましょう。
章1のタイトル
それでは最初に、文字コードとはそもそも何なのかを確認していきましょう。
✅ 本記事は、ASCII、ISO、Unicode、JISなどの文字コードについて説明しています。文字コードとは、コンピュータ上で文字を表すための符号体系です。
✅ ASCII(American Standard Code for Information Interchange)は、7ビットで128文字を表す文字コードです。ISO(International Organization for Standardization)は、8ビットで256文字を表す文字コードで、ASCIIを拡張したものです。Unicodeは、16ビット以上で最大65,536文字を表す文字コードで、世界中のほとんどの文字をカバーしています。
✅ JIS(Japanese Industrial Standards)は、日本の産業規格であり、ASCIIやISOに基づいており、日本語の文字を表すために使用されています。具体的には、JIS X 0208は半角カナや特殊記号を含む128文字、JIS X 0212は漢字を含む6,349文字、JIS X 0213は追加漢字を含む7,928文字を表しています。
さらに読む ⇒文字コードは、コンピュータ上で文字を扱うための符号体系のことです。難しいですねぇ。
{Dataより作成した要約文}。{Dataより作成した要約文}。{Dataより作成した要約文}。
まじウケるー。文字に番号振ってるだけやん!
いやいや、それだけでコンピュータ上で文字を扱えるようになるんだからすごいもんですよ。
ほほー、コンピュータも頭がいいんやのう。
章2のタイトル
文字コードには、ASCIIやUnicodeなど、さまざまな種類があります。
✅ 文字コードは、文字をコンピュータで処理や通信するために、文字に番号を割り当てたものです。これにより、文字を数値として扱えるようになり、データの送受信や保存が可能になります。
✅ ASCIIなどの1バイト文字コードは、英語などのアルファベットや記号を表現するのに適していますが、漢字などの多種類の文字を表現するには不十分です。そのため、2バイト文字コードやUnicodeなどの複数の符号位置を組み合わせて1文字を表現する複雑な文字コードが開発されました。
✅ Unicodeは、世界中の文字を網羅する国際的な統一文字コードですが、その構造は複雑です。1文字が複数の符号位置で表現されることもあり、プログラミング上は注意が必要です。例えば、濁点や半濁点付きの文字は、ベースとなる文字と合成用の記号を組み合わせて表現されます。また、絵文字の中には、複数の絵文字を組み合わせて表現するものもあります。
さらに読む ⇒ASCIIはアルファベットや数字を扱うのに適していますが、日本語などの多種類の文字を扱うには不十分です。
{Dataより作成した要約文}。{Dataより作成した要約文}。{Dataより作成した要約文}。
日本語って難しいんやから、専用のコードが必要なんやね。
そうですね。そこで登場したのがJISコードというわけですね。
JISコードって、日本生まれの文字コードなんやな。
章3のタイトル
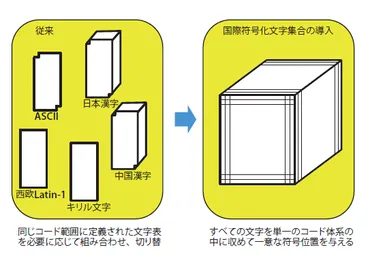
Unicodeは、世界中の文字を網羅する文字コードです。

✅ 文字コードとは、コンピュータシステムにおいて文字情報を処理するために使用する数値(符号)のこと。文字コードには、ASCII(米国の国内規格)、ISO/IEC 8859(欧州各国の言語に対応)、JIS X 0201(日本語の7ビットコード)、JIS X 0208(日本語の2バイトコード、94×94の漢字集合)、JIS X 0213(日本語の2バイトコード、94×94×2の漢字集合、非漢字も収録)、EUC-JP(Extended Unix Code for Japanese)、Shift_JIS(Shift Japanese Industrial Standards)、UTF-8(Unicode Transformation Format - 8ビット)、UTF-16(Unicode Transformation Format - 16ビット)などがある。
✅ 日本語関連の文字コードとしては、JIS X 0201、JIS X 0208、JIS X 0213、EUC-JP、Shift_JIS、UTF-8 などがある。JIS X 0201 は日本語の7ビットコードで、主に片仮名や記号に使用される。JIS X 0208 は日本語の2バイトコードで、94×94の漢字集合を定義している。JIS X 0213 は日本語の2バイトコードで、94×94×2の漢字集合を定義している。EUC-JP は日本語の8ビット符号化方式で、ASCII、JIS X 0208、JIS X 0213 を符号化できる。Shift_JIS は日本語の8ビット符号化方式で、JIS X 0201 と JIS X 0208 を符号化できる。UTF-8 は日本語の8ビット符号化方式で、Unicode を符号化できる。
✅ Unicode は、世界中の文字をひとつのコード体系で扱えるように設計された文字符号化方式である。Unicode は、17面あるうちの最初の第0面を基本多言語面(BMP)と呼び、BMP には ASCII、欧州言語、キリル文字、アラビア文字、漢字など、世界でよく使われる文字が収録されている。BMP に収録されていない文字は、追加面と呼ばれる第1面以降に収録されている。追加面には、ハングル、ヒンディー語、タイ語、ギリシャ語、ヘブライ語など、世界各国の文字が収録されている。Unicode には、UTF-8、UTF-16 などの符号化方式がある。UTF-8 は可変長符号化方式で、1バイトから4バイトを使用して文字を符号化する。UTF-16 は可変長符号化方式で、1バイトから2バイトを使用して文字を符号化する。
さらに読む ⇒Unicodeは、1つの文字が複数の符号位置で表現されることもあります。ややこしいですねぇ。
{Dataより作成した要約文}。{Dataより作成した要約文}。
えー、なんでそんなややこしいことするの?
Unicodeは世界中の文字を扱えるように作られてるから、しょうがないんですよ。
せやけど、プログラミングする時は気ぃつけなあかんのやな。
章5のタイトル
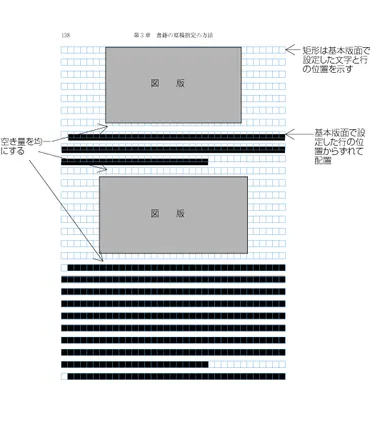
Wordでは、「Enterキー」と「Shift」+「Enterキー」で改行と改段落を切り替えることができます。

✅ Word では、「Enter キー」を押すと「改段落」になり、段落が新しく作成されます。一方、「Shift」+「Enter キー」を押すと「改行」になり、段落は作成されません。
✅ 「改行」と「改段落」の違いは、通常はあまり問題になりません。しかし、アウトライン機能を使用する場合は明確に区別する必要があります。アウトライン機能では、段落を単位として操作するため、「改行」と「改段落」を区別しないと、正しく操作できない場合があります。
✅ 段落を正しく設定しておけば、段落記号や段落番号を自由に使用したり、インデント処理を行ったりすることができます。段落記号や段落番号は、文章を構造化したり、見やすくしたりするために使用されます。また、インデント処理は、文章の特定の部分を目立たせたり、段落を区別したりするために使用されます。
さらに読む ⇒改行と改段落の違いは、通常はあまり問題になりませんが、アウトライン機能を使用する場合は注意が必要です。
{Dataより作成した要約文}。{Dataより作成した要約文}。
ほぇー、Wordって意外と細かいんやな。
そうなんですよ。細かい作業をするときは、改行と改段落を意識することが大切です。
ほほー、勉強になるのう。
文字コードの基礎知識を身につければ、コンピュータ上で文字をより便利に扱うことができます。
💡 ASCII、Unicode、JISコードなど、さまざまな文字コードの特徴を理解しましょう。
💡 改行と改段落の違いにも注意して、Wordを効率的に使いこなしましょう。
💡 文字コードの知識は、コンピュータを使いこなす上で欠かせません。